� language model Pr(T), i.e. to model the structure of the target
sentence at all levels (lexical, syntactic, semantic,...).
� statistical learning: the
parameters of the language, alignment and lexicon models must be learned from
example data and resources such as monolingual and bilingual training data,
bilingual dictionaries, morpho-syntactic analysers etc.
� generation (or search)
task: the target sentence with the maximum probability has to be determined. This generation must be able to handle large
vocabularies.
� integration of recognition
and translation: when handling speech input rather than text input, the
statistical approach as to take into account both the ambiguities of the speech
recognition process and the ungrammatical and disfluent nature of the spoken
language.
The principles on which the statistical approach is
based were worked out only around 1990. Considerable progress has been made
since then due to improvements in the underlying models and algorithms and to
the availability of bilingual parallel corpora and greater processing power.
Recently, for written language translation with large vocabularies
(about 50000 words), it was also found that, as a result of this progress, the
statistical approach is able to produce competitive results with conventional
translation systems that had been optimized over decades.
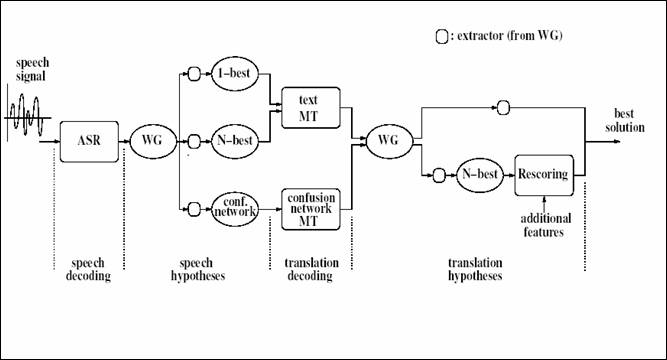
Figure
1: A spoken language translation chain including speech recognition and
translation under development at ITC-irst.
In Figure 1 the spoken
language translation chain under development at ITC-irst is described.
4. Speech Translation Activities in Europe
Language is a topic of major importance for the construction of the
European Union, which is of economical, cultural, political and social nature.
The effort to address such crucial issue appears to be too large for the
Commission alone, and it seems to be necessary to have this effort shared
between the Commission (which has the duty to ensure a good communication with
the member states, and among the member states), and the member states which have
to preserve and promote their language(s), and through their language(s), their
culture. For this reason the Commission, in the V and VI frameworks, identified
HLT as strategic objective.
When there were just 15 member states with 11 official
languages, the European Union spent 549 million euros on translation. With 25
states since May of 2004, the EU now has 20 official languages. And the number
of language pairs for translation jumped from 110 to 380. The economic costs of
language translation are very large, and growing.
Consider another aspect of the language equation:
recent studies show that European citizens prefer Web sites in their own
language. Most would not agree to filling in a tax form in a language not their
own. Understandably, most people would object to a lack of newspapers in their
own language. The importance of language will become evermore critical as the
EU moves forward as an information society. Language is the main instrument of
communication for work, travel, and home. The social costs of language
translation cannot be ignored.
Clearly public institutions and the private sector
need a solution to the issue of language translation. Automated language
processing technology can provide solutions for translation, information query,
and other cross-lingual applications. In fact, language technologies have been
a strategic research topic since the V Framework program. The result is that
some European public research institutions and private companies have developed
leading language technologies. They are competing well against US institutions
at the technology level.
In
Performance evaluation is one of the most important
objectives of the TC-STAR (Technology and Corpora for Speech to Speech
Translation) project. TC-STAR is a project funded by the European Commission
within the �VI Framework Programme. The
TC-STAR Consortium brings together prominent European players in the speech
technology field, including both basic research institutes and universities, as
well as large companies with years of experience in the field. The Consortium
itself is a first step towards reinforcing the European Research Area, and
offers a unique opportunity to place
TC-STAR has the ambitious goal: to make a breakthrough
in SST research that significantly reduces the performance gap between humans
and machines. TC-STAR represents a long-term effort focused on advanced
research in core language technologies: speech recognition, speech translation,
and speech synthesis.
In the TC-STAR project two
translation tasks are investigated:�
translation of speeches delivered at the�
European Parliament during plenary sessions� and a broadcast news translation task. For
the European Parliament Plenary Session (EPPS) task, two directions of
translation are considered: from Spanish to English and from English to
Spanish. In the broadcast news�
translation task,� translation
from Chinese Mandarin to English is considered. Within the project, in March
2005, an evaluation campaign was carried out to evaluate performance of spoken
language translation systems developed by several� research groups. As an example, on the EPPS
task, by assuming manual segmentation in turns,�
the best system can get 65% of the words correct, ignoring the word positions.
Even if this result is far to be perfect, it is very encouraging as it is
achieved on �a real-life task (see http://www.tc-star.org/documents/deliverable/Deliv_D5_Total_21may05.pdf).
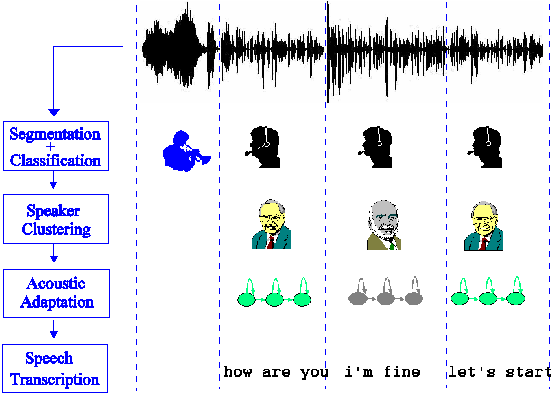
� ������������� ��Figure 2: Block diagram of �the automatic
transcription process.
5. ITC-irst Transcription
System
The
ITC-irst transcription system [4,5,6] includes all the main processing steps
outlined Section 2, that make it possible to accept a signal of unknown
contents, including non-speech portions, and produce a transcription of the
speech portions, along with a classification of signal portions with a
combination of different categories: male/female voice, wideband/narrowband
speech, silent/noisy/background, etc. A block diagram of the transcription
process is depicted in Figure 2.
Speech
recognition exploits context dependent Hidden Markov Models, a 64K-word trigram
language model (LM), beam-search Viterbi decoding, and maximum likelihood
linear regression (MLLR) acoustic model adaptation. Speech segments are
transcribed performing two decoding passes interleaved by cluster-based
acoustic model adaptation. Word transcriptions of the first decoding step are
used as supervision for acoustic model adaptation.
The
acoustic front-end uses a sliding window of 20ms, with a step of 10ms, to
compute 13 mel-scaled cepstral coefficients and their first and second order
time-derivatives. Mean normalization is applied to static features.
For
transcription of the news programs broadcasted by RAI, the major Italian
broadcaster, acoustic models are trained through a speaker adaptive acoustic
modelling procedures [7] by exploiting recordings of from broadcast news
programs. Two sets of acoustic models were trained by exploiting for each set
about 140 hours of speech. The LM was estimated on a 226M-word corpus including
newspaper articles, for the largest part, and BN transcripts. Finally, the LM
is compiled into a static network with a shared-tail topology [5].
By
considering entire broadcast news programs, the system achieves, on average, a
word error rate around 12.9%. Details on performance achieved are reported in
Table 1. Reported results are for a single pass decoding process and for a two
passes decoding process exploiting cluster-based speaker adaptation. In the row
New most recent recognition results
are reported which can be compared with official results obtained on this task
2 years ago and reported in the row Old.
Relative reductions in word error rate are also reported in the Table.
Recognition results are reported by considering entire broadcast news programs
(column Overall) and by considering
separately wideband and narrowband speech. Reported relative reductions of the
word error rate show that significant advances have been made under all
conditions. In particular, for the reference transcription system
configuration, which makes use of two decoding steps, a relative word error
reduction 19.4% can be observed.
�
|
|
Wideband |
Narrowband |
Overall |
|||
|
|
|
|
|
|
|
|
|
Old |
15.5 |
14.2 |
25.2 |
22.4 |
17.6 |
16.0 |
|
New |
14.6 |
11.7 |
21.0 |
17.1 |
16.0 |
12.9 |
|
Relative reduction |
5.8% |
17.6% |
16.7% |
23.7% |
9.1% |
19.4% |
���������������� Table 1: Word error rates achieved on the Italian broadcast news
transcription task.
Currently, the ITC-irst transcription system is in use
at RAI for automatic indexing of huge archive of audio-visual� documents in the context of an information
retrieval application [8].
The
ITC-irst transcription system was recently adapted to cope with transcription
of speeches delivered at the Italian Parliament Assembly. Preliminary
transcription experiments resulted into a word error rate of about 12%. Work is
ongoing to further tune the system components to this specific task. The aim is
to develop a system for helping professionals in quickly producing high quality
minutes of the parliamentary debates.
6. References
[1]
Franz Joseph Och, Hermann Ney.
A
Systematic Comparison of Various Statistical Alignment Models. Computational
Linguistics 29(1): 19-51 (2003).
[2]
Stephan Vogel, Alicia Tribble. Improving
Statistical Machine Translation for a Speech-to-Speech Translation Task. In Proceedings
of ICSLP-2002 Workshop on Speech-to-Speech Translation. Denver, CO.
September 2002.
[3]
Lazzari G. Spoken
Translation: Challenges and Opportunities. In B.
Yuan, T. Huang, X. Tang (eds.) Proceedings of 6th
International Conference on Spoken Language Processing,
[4]
F. Brugnara, M. Cettolo, M. Federico and D. Giuliani. Advances in
Automatic Transcription of Italian Broadcast News. In Proceedings of ICSLP,
[5]
N. Bertoldi, F. Brugnara, M. Cettolo, M. Federico, and D.
Giuliani. From
broadcast news to spontaneous dialogue transcription: Portability issues. In
Proceedings of ICASSP,
[6] F.
Brugnara, M. Cettolo M. Federico and D. Giuliani. Issues in Automatic
Transcription of Historical Audio Data. In Proceedings of ICSLP, Denver, CO, September,
2002, pp. 1441-1444.
[7]
D. Giuliani and M. Gerosa and F. Brugnara. Speaker
Normalization through Constrained MLLR Based Transforms. In Proceedings of ICSLP,
[8]
�N. Bertoldi, F.
Brugnara, M.Cettolo, M. Federico, D. Giuliani E. Leeuwis and V. Sandrini. The ITC-irst
News on Demand Platform. In Proceedings
of the European Conference on Information Retrieval Research,